People store large quantities of data in their electronic devices and transfer some of this data to others, whether for professional or personal reasons. Data compression methods are thus of the utmost importance, as they can boost the efficiency of devices and communications, making users less reliant on cloud data services and external storage devices.

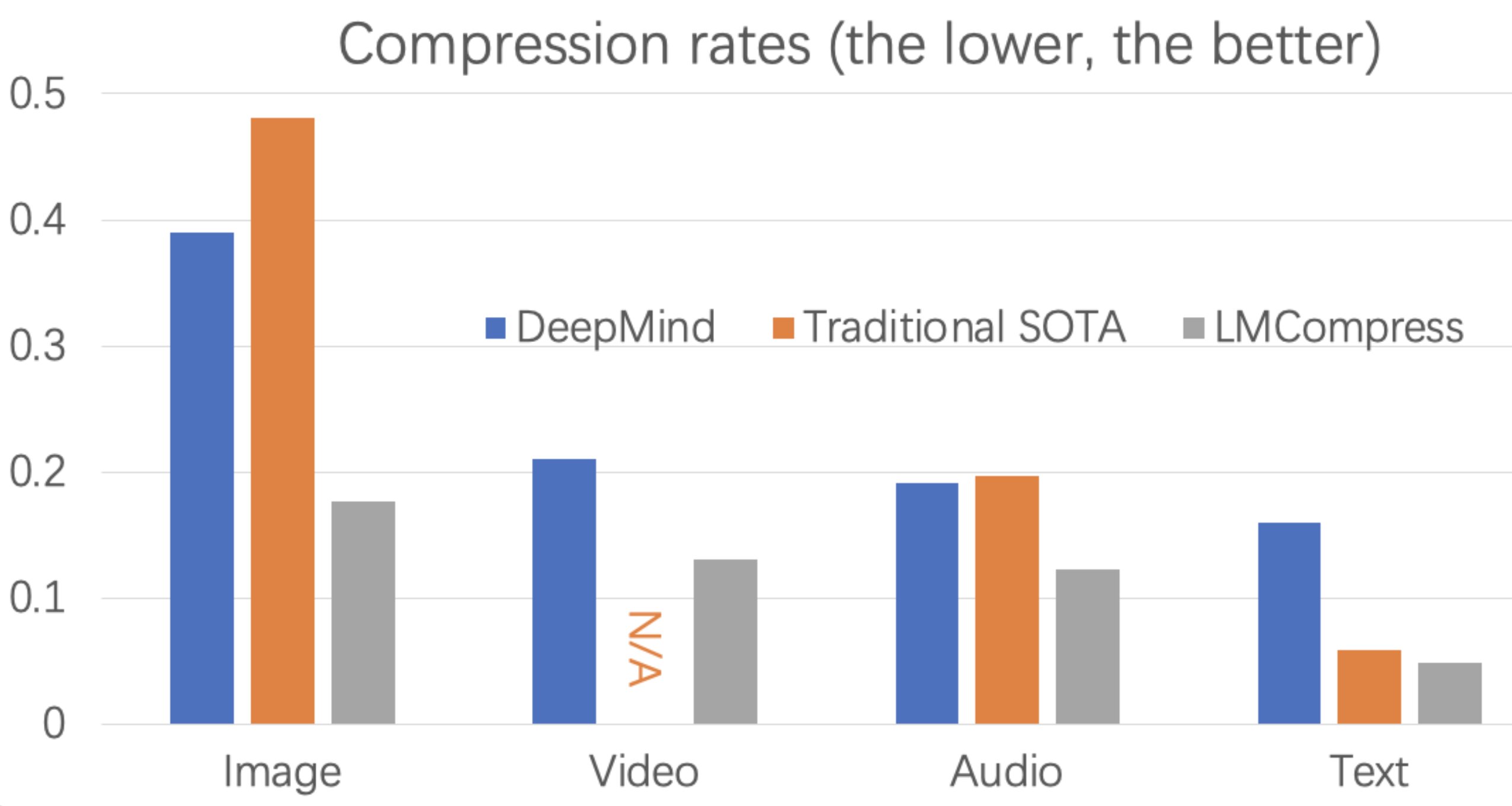
This is not new knowledge and predates the current LLM fad.
See the Hutter prize which has had “machine learning” based compressors leading the ranking for some time: http://prize.hutter1.net/
It’s important to note when applied to compressors, the model does produce a code (aka encoding) that exactly reproduces the input. But on a different input the same model is unlikely to produce an impressive compression.
Can you define “compressors” here? (Google was unhelpful.)
I could have said it better.
I mean compressor as half of a compression/decompression algorithm. The better way I should have worded it is: when you apply machine learning to a compression problem, you can do it lossless…your uncompressed output will be identical to the input, every time.
“NNCP” is a good search term to learn more, specifically about how this works.