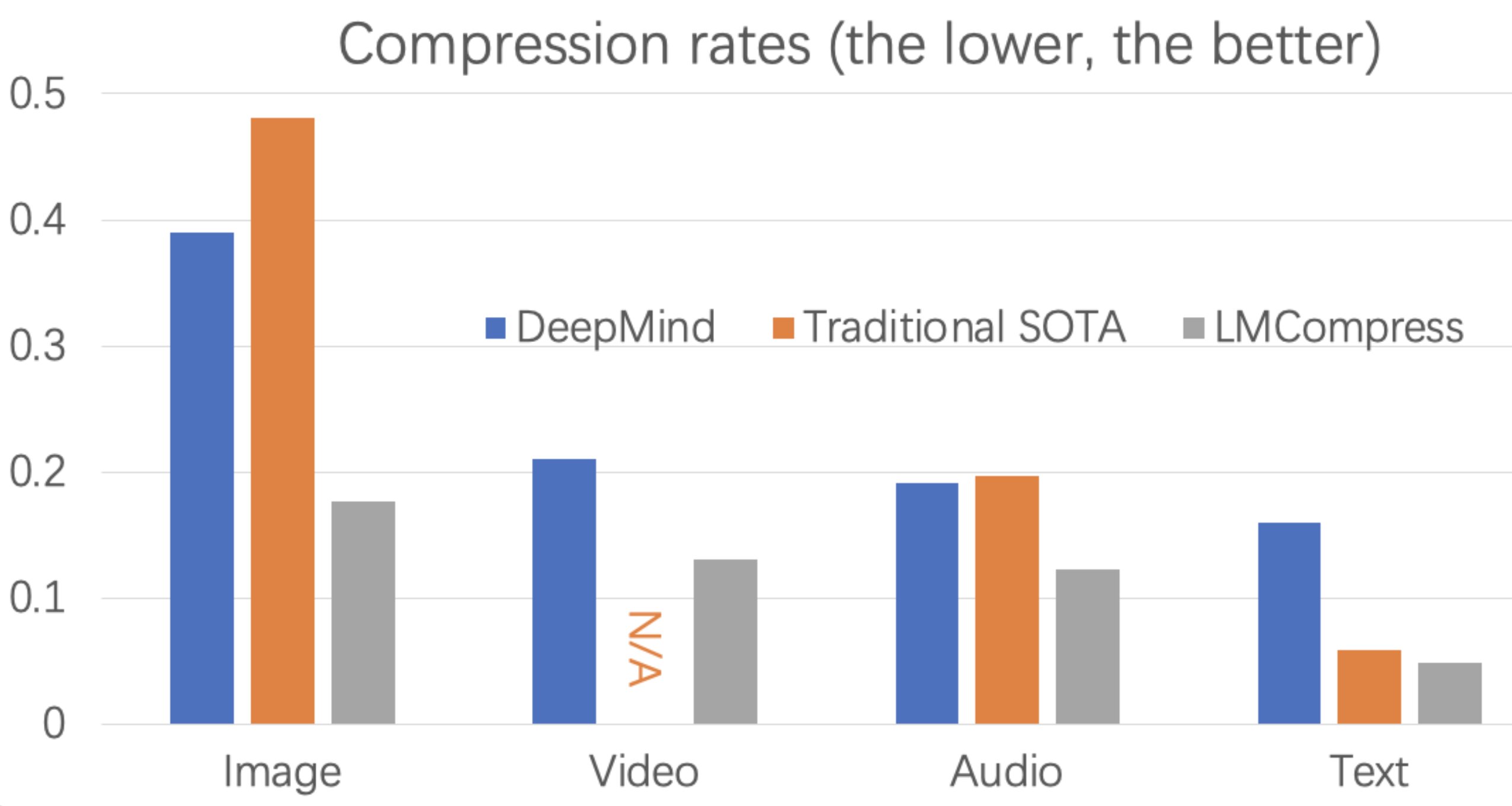
People store large quantities of data in their electronic devices and transfer some of this data to others, whether for professional or personal reasons. Data compression methods are thus of the utmost importance, as they can boost the efficiency of devices and communications, making users less reliant on cloud data services and external storage devices.

I’m guessing that exactly the same LLM model is used (somehow) on both sides - using different models or different weights would not work at all.
An LLM is (at core) an algorithm that takes a bunch of text as input and produces an output of a list of word/probabilities such that the sum of all probabilities adds to 1.0. You could place a wrapper on this that creates a list of words by probability. A specific word can be identified by the index in the list, i.e. first word, tenth word etc.
(Technically the system uses ‘tokens’ which represent either whole words or parts of words, but that’s not important here).
A document can be compressed by feeding in each word in turn, creating the list in the LLM, and searching for the new word in the list. If the LLM is good, the output will be a stream of small integers. If the LLM is a perfect predictor, the next word will always be the top of the list, i.e. a 1. A bad prediction will be a relatively large number in the thousands or millions.
Streams of small numbers are very well (even optimally) compressed using extant technology.