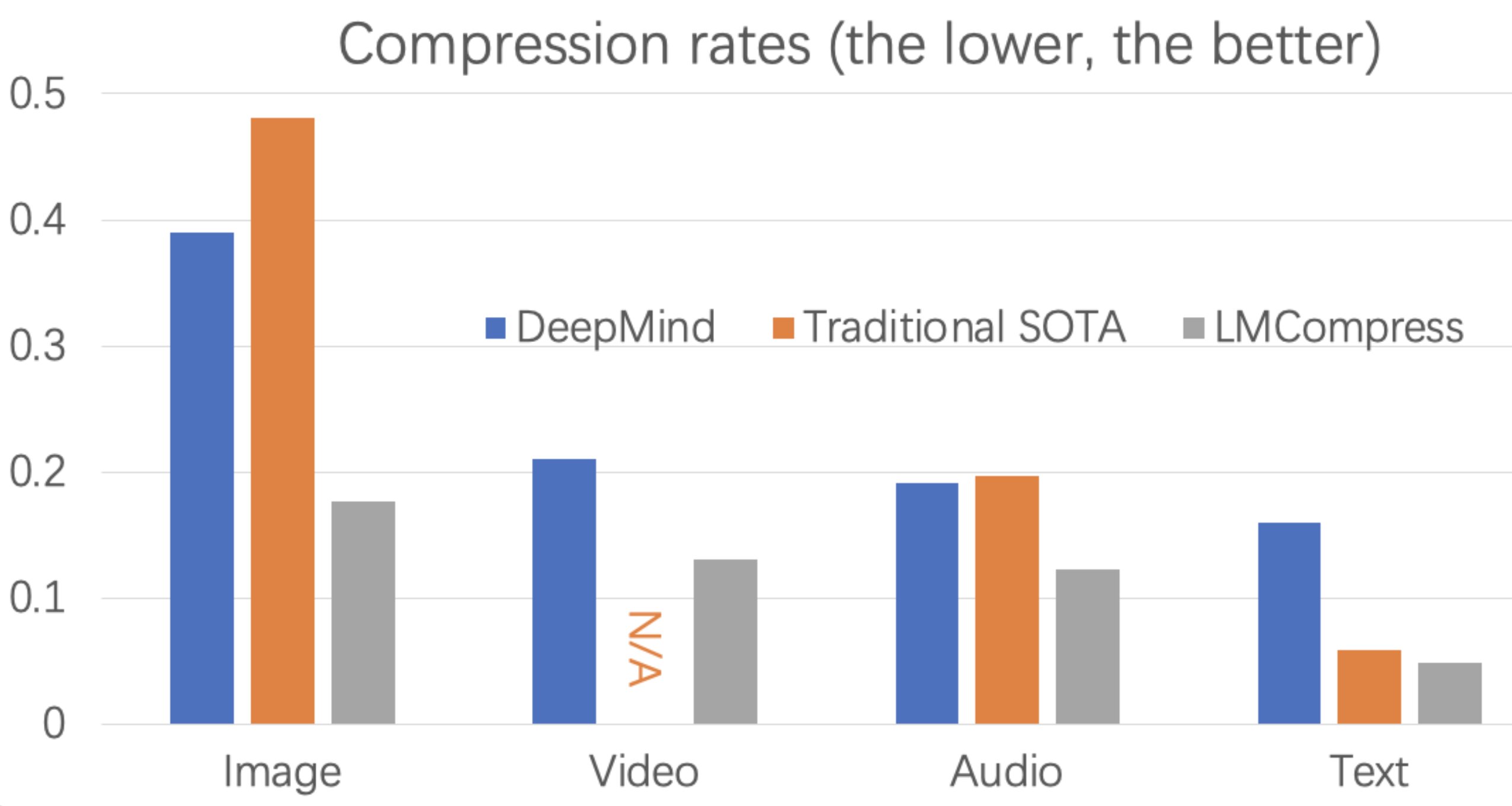
People store large quantities of data in their electronic devices and transfer some of this data to others, whether for professional or personal reasons. Data compression methods are thus of the utmost importance, as they can boost the efficiency of devices and communications, making users less reliant on cloud data services and external storage devices.

So if I have two machines running the same local LLM and I pass a prompt between them, I’ve achieved data compression by transmitting the prompt rather than the LLM’s expected response to the prompt? That’s what I’m understanding from the article.
Neat idea, but what if you want to transmit some information that an LLM can’t tokenize and generate accurately?
And how do I get the prompt that will reliably generate the data from the data? Usually for compression we do not start from an already compressed version.